Wordle & `ripgrep`
- Wordle
- First Guess:
- Second Guess:
- Third Guess:
- Using only grep:
- Fourth Guess: Almost Won!
- Fifth Guess: Time for Plan B
- Sixth Guess:
- Seveth Guess:

Wordle
I recently decided to play Wordle, again engrossing myself in a fad after hype train has left. 👾🎉
⬜ ⬜ 🟨 ⬜ 🟩
⬜ 🟩 🟨 ⬜ 🟩
⬜ 🟩 ⬜ 🟩 🟩
⬜ 🟩 🟩 🟩 🟩
⬜ ⬜ ⬜ ⬜ 🟩
⬜ ⬜ ⬜ 🟨 🟩
🟩 🟩 🟩 🟩 🟩
⌨
Of course, I decided to play the Esperanto version, of which there are many, including Vortjo, Wordleo, and Vortlo. I won't name which one to give you a chance to try them for yourself.
The same way that my cleverer/lazier friends, so too did I; instead of being a training tool to improve my linguistic abilities, I decided to find out the easiest way I could find the right word. Quickly.
Enter Linux
If the only tool you have is a hammer, every problem looks like a nail.
📌🔨
What's interesting is that everyone who tries to cheat this game1 does so in a completely different way (that's all to familiar to them, individually). Mathematicians have cracked it with math, but I, as a programmer, used Linux cli tools. 🐧
Cheating Wordle with Linux
When trying to beat any language game, it's important you start with a dictionary! 📖📚 And an Esperanto dictionary at that. Fortunately, I have exactly that lying around from another project I created.
Time to dive into the terminal2!
My dictionary consists of a json file with Esperanto word roots and their English translation.
cat *
...
"vol": "want",
"volv": "roll",
"vom": "vomit",
"zorg": "care",
"zum": "buzz/hum"
}
cat and awk
To filter out the translations, we can use awk. This command is to print the first column from the output. (Yeah, awk is 1-indexed, unlike the majority of programming languages)
cat * | awk '{ print $1 }'
...
"vol":
"volv":
"vom":
"zorg":
"zum":
}
First Guess:
But we only want words of a certain length (however many boxes there are per row in our Wordle version). So we want 5-letter words, with 3 additional characters for the surrounding " and ": parts, and minus 1 because the word roots in my dictionary are missing the last letter3.
cat * | awk '{ print $1 }' | awk 'length==3+5-1'
...
"vend":
"venĝ":
"venk":
"verŝ":
"volv":
"zorg":
Time to hazard a guess:
Not bad, however Esperanto has a limited number of word endings, and O if perhaps the most common. So no we want to search for words with certain letters, but at the same time we want to filter out certain letters.
Second Guess:
grep
(rip)grep enables you to search text in a far more robust and powerful manner than Ctrl+F. To search for a string, you just need to type it out after the command. To filter out characters, you can use rg -v / grep -v
cat * | awk '{ print $1 }' | awk 'length==3+5-1' | rg -v '[bir]' | rg 'e'
...
"temp":
"tend":
"vejn":
"vesp":
"veŝt":
The [ and ] mean that the letters between them belong to a set, not a string. So rg -v [bir] ignores any line that has the letters b, i, or r in any order.
Typing rg -v 'bir', on the other hand searches for that exact string bir, and filters out words like birdo, barbiro, and Birmo.
So the [bir] part has the exact same output if typed [rib] or [irb].
Snagged one letter, and know another.
Now we want words with the letter E and N, but this will be a little different than filtering out sets of letters.
Third Guess:
The [] set notation won't help anymore because we want words with E and N, not E or N, so additional grep commands are needed to make sure all the letters are present.
cat * | awk '{ print $1 }' | awk 'length==3+5-1' | rg -v '[birmu]' | rg 'e' | rg 'n'
...
"sven":
"tent":
"vend":
"venĝ":
"venk":
If you want to randomly select an item from the printed list, you only need to ad | shuf | head -n 1 to shuffle the words around, and choose the first one.
The board is getting greener and greener. 😊
Using only grep:
Instead of cat | awk, we can do the search part purely with grep. By default ripgrep4 searches each file in the current directory, so that takes care of the cat * part.
But how can we search for just the word roots and not their translatoins? In the json abose, you can see there is a different character pattern around the definitions because they are dictionary keys (so there is an : after the final "). What we want is patters of 4 letters between the strings " and ":.
In regex-lingo5 . matches any character, and the {4}-part means to check for the pattern before it 4 times. In English, ".{4}": means to search the pattern: "▫▫▫▫":, (with any characters in between).
rg -Io '".{4}":' | rg -v '[birmulo]' | rg 'e' | rg 'n'
...
"scen":
"senc":
"sens":
"tend":
"vejn":
Now all the non-grep commands are gone, and the command length is overall shorter, but there are still too many greps!
Fourth Guess: Almost Won!
Now that we have more information about hte location of the letters, it's time to be more intelligent about how we're using it (and also make our command shorter)!
{4} means to match the pattern before 4 times, so ".{4}": is the same to grep as typing "....":. Knowing that, instead of matching any letter, we can change the . to the specific letters we already know.
Now the grep command clearly mirrors the game board itself:
rg -Io '".e.n":' | rg -v '[birmulo]'
"vejn":
Excellent! There was only one result output from that command, so we must've found our word! 🎉
Fifth Guess: Time for Plan B
Hmm... My dictionary seems to be missing that word. 😞
Not all is lost; we can still pull the trick of using a guess up on a word with letters we haven't used at all yet, so we can check as many remaining letters as possible.
rg -Io '"[^birmulone]{4}":'
...
"stat":
"ŝtat":
"takt":
"task":
"vaks":
New syntax: The ^ means we want none of the letters of the set. This is different from rg -v because the we want the " + ": parts, it's only the letters in-between we want to filter out.
We managed to eliminate some letters, including the last vowel6.
Sixth Guess:
I'm going to march on with the same strategy as before -- there's aren't too many words remaining without all these letters.
rg -Io '"[^birmuloneŝt]{4}":'
...
"saŭc":
"spac":
"vaks":
"fajf":
"paŭz":
🤔🤔 So the missing letter was S?
The algorithm above shoudl've already found this word...
Seveth Guess:
Finally! Seems like Plan B worked, but DuoLingo never taught me this word! 🦉
What is a Sejno?
According to Wikipedia:
The Seine is some river in France, from this famous painting:

Here's a game that played me! I thought I was here to improve my linguistic skills, but Wordle is schooling me in geography instead 🌎🌍🌏
The Real Sejno:
After further research I found another definition; Wikipedia saves us again!
"A seine is a type of net for river fishing."
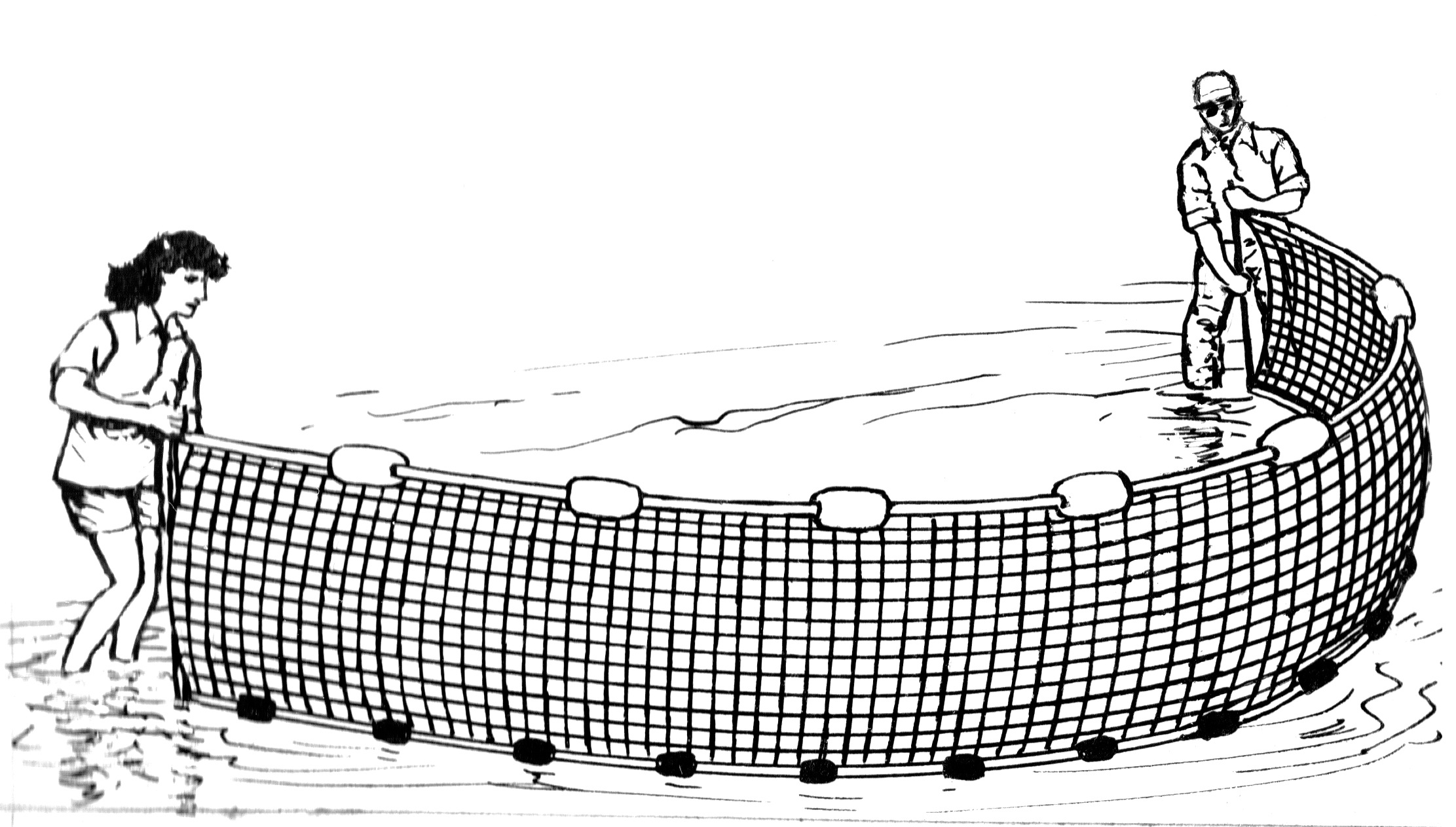
Well, 😅 seems like it is a real word.
Thanks for reading; I hope you learned something either about cli programs, or about Esperanto.
In the sense of finding the word with as little effort as possible.
The last letter of an Esperanto word us grammatical in nature. (e.g., words ending in -o are nounds, and -a words are adjectives)
Esperanto only has 5 vowels: a, e, i, o. English has the same 5 letters for vowels, but has 11+ vowel sounds.
I use ripgrep (rg) instead of the classical grep and bat because.. well, they were written in rust, and are more modern. Still waiting on a replacement for awk...
A good source for learning, checking, and practicing regexes is regexr.com.